

The Hazards of Using Big Data
Despite (or maybe because of!) having a technical background, my goal for the AI release was to develop materials related to the ethics and the effects of having more and more automation in the world. It is critical that as individuals, we can be “informed citizens” and my idea was (and still is) to have a course dedicated to giving students a basic understanding of the pros and cons of the various current events. A key learning objective of the course would be to define enough vocabulary terms so that they are able to, for example, critically analyze the contents of a newspaper or magazine article.
That said, most of these topics can also be presented in isolation and within the context of other courses. Below are some of the resources I’ve developed to aid teachers in presenting this material. Some specific existing courses where I imagine these resources could be useful include 420-BWC (Introduction to Computers), 420-BXC (Introduction to Programming), or an ethics course such as 345-BXH (Applied Ethics). They also can be presented in many different Computer Science department courses as lessons related to the importance of asking critical questions about how one’s work will be used in practice.
Resources
This is probably the most important module as it aids in understanding the limitations of big data. We should not just “throw the data into a machine learning algorithm and see what it comes up with.” Doing this is extremely dangerous for several reasons. For starters, this can result in unfair, biased, and discriminatory conclusions that unfairly target groups. These groups are also usually the same groups that are already underrepresented in many places and the machine learning algorithms, when applied recklessly, only serve to exacerbate this.
To understand this, we must consider that while there may be data to support a claim, there are frequently underlying reasons (hidden variables) that lead to the results. This is the idea of “correlation vs causation.” An example of this is given in the slides: It turns out that ice cream sales and shark attacks occur at the same time (due of course, to the hidden variable “summer”). It would be wrong to conclude that since they occur at the same time, that we should ban ice cream sales to reduce shark attacks. Another famous example of this is the claim that pirates prevented global warming (see graph below).
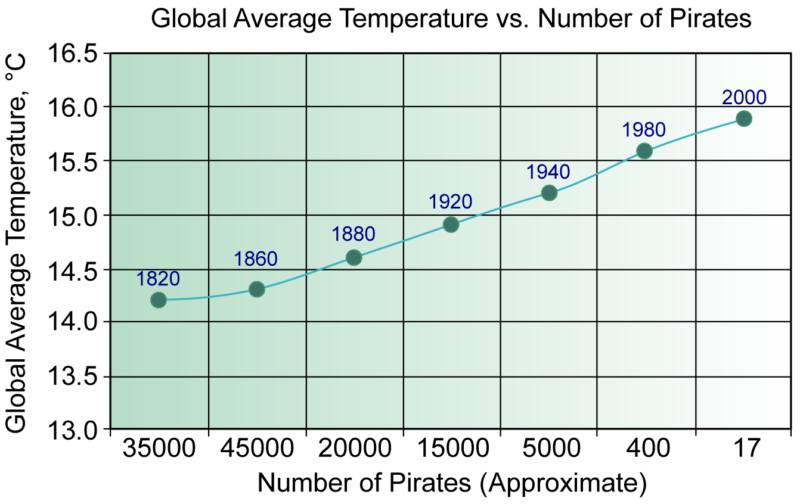
Back when there were more pirates on Earth, the global temperature was less. But this is obviously not a question of causation. Hence we always should seek to explain these data phenomena and not just “trust the data.”
Additionally, there is a risk of “p-hacking” which results from the concept of “statistically significant.” In general, we say results are “statistically significant” if we believe that the results would only occur by chance 5% of the time. For example, in medical studies, participants are divided into two groups: a control group that receives a placebo pill and a group that receives the medicine. If the group receiving the real pill has improved outcomes (compared to the control group) that would only occur 5% of the time in the case that the pill did nothing at all, then they will conclude that the results are statistically significant and that the pill is useful.
Essentially, what this can end up meaning though, is if you test 1000 different hypotheses, then inevitably some of them will be true by accident. If something has a 5% chance of occurring, and you try it 1000 times, it will certainly occur several times. For more on p-hacking, please see the following link https://fivethirtyeight.com/features/science-isnt-broken/#part1
In this set of slides, there is a discussion of the term “Big Brother” as a proxy term for “surveillance” and the notion that everything we do is being stored. What obligation do private companies such as Google have towards maintaining our privacy? What about the internet service providers? Should they be required to purge our web histories after a certain amount of time?
Data tracking has some positive uses; Google has developed an application called “Google Flu Trends” (which was later removed). The idea was to prevent the spread of a disease by quickly identifying trends such as an increase in search queries that suggest illnesses (e.g. “is one degree above normal a fever?”). Who should own this data though? While it’s easy to say private corporations shouldn’t hold it, big government also is a problem. (In fact, the original use of the term Big Brother was for government.)
In this (shorter) set of slides, some of the pros/cons of facial recognition are discussed. There are some advantages of using facial recognition, for example, to catch “criminals.” But these advantages come with huge risks (police state, constant advertisement). An additional question not mentioned in the slides is “should parents be allowed to post pictures of their children to social media?” This is being done, without the consent of their children (who cannot provide informed consent). These pictures can then be used by future algorithms (which will no doubt be better than today’s algorithms) to identify their children in many ways.
This slide deck was the first part of a presentation given at Dawson’s Ped Days in 2020. It provides an overview of the history of text generation systems as they improved from early generation ones to today’s ones, capable of writing very advanced and detailed texts. This talk also discusses an important notion in AI called the “Turing test” named after Alan Turing. The idea is that an AI system is considered to pass the test if a user of the system cannot determine whether the system is an AI or a human.
Turing test:
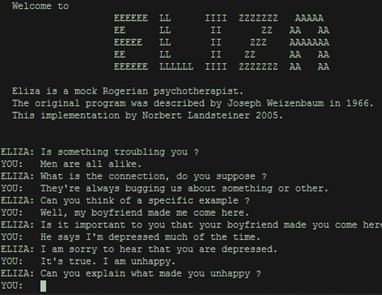
Below is an amusing chat between Eliza, a chatbot imitating a psychologist, designed in the 1960s at MIT, and a human. The chatbot was designed to follow a script.
Other Interesting Links
Here are some other interesting links, relevant to artificial intelligence.
How do we program self-driving cars? We frequently make split-second “decisions” as drivers of cars. If a car stops short in front of us, and we swerve to avoid it—but hit someone else in the process—we would normally write this off as a “reflex” (hence the term “accident”). However, in designing self-driving cars, we are forced to program these choices ahead of time. The video discusses some ramifications of this. The scholars featured in this video also did a massive survey of people, from across the globe, to understand their personal choices in these situations. Although the data is interesting, this begs the very important question “do we really want to determine our morals based on majority rules?” Such “reasoning” has been the foundation of many of the world’s worst historical atrocities.
Deep-blue vs Kasparov: This is an interesting summary of the famous 1996 chess match between IBM’s Deep Blue and Garry Kasparov, the world champion of chess at the time. This match was personally interesting for me, and got me interested in artificial intelligence because I play chess competitively. It’s interesting that at the time of the event, the main advantage the computer had was a psychological one—it didn’t get tired! Today’s computers (such as Alpha-Go) are so much more powerful that there is simply no contest in chess match between “man vs machine.”
Initial Presentation: Here is a presentation I gave during one of the meetings of Dawson’s AI-themed community of practice. It is included here for completeness as well as context. During this presentation, I discussed my goals for the release

